
TAOCP 1.1 算法
看一本书上的介绍知道了这本书,看价格太贵就只买了第一卷。买来翻了几页感觉很庆幸,幸亏自己只买了第一卷。第一章的第一节都看了好久,完了还不知道自己理解的对不对。
这里记录下书中的主要内容及比较难理解的地方,作为笔记。
1.1 算法
算法 是计算机程序设计的基本概念。
algorithm 这个词更古老的词形是 algorism ,它表示用阿拉伯数字进行的算数运算。在中世纪,珠算人员用算盘进行计算,而数算人员( algorist )则依据十进制计算规则用阿拉伯数字做计算。algorism 这个词的真正来源是波斯知名教科书作者的名字 Abū ʿAbd Allāh Muhammad ibn Mūsā al-Khwārizmī (中文也译作 花拉子米)。他关于印度和阿拉伯数学的著作被译作拉丁文,书名是《印度计算法》( Algoritmi de numero Indorum )。algoritmi 是其名字的拉丁文译名,后来演变成 algorithm (算法)一词。
1.1E 欧几里得算法
1.1E:表示第 1 章第 1 节的算法 E。
欧几里得算法:给定两个正整数
步骤
- E1. [ 求余数。 ] 用
除 ,令 为余数。(我们将有 。 ) - E2. [ 余数为
? ] 如果 ,算法终止。 是答案。 - E3. [ 减少。 ] 置
,然后返回步骤 E1。 ▋
本书中描述算法的格式都是这个样子的。应该还是很直观的,就不多做解释了。
如果
- E0. [ 保证
。 ] 如果 ,交换 。
我写的 Java 版代码:
这里没有使用变量的交换,而是使用递归实现了类似的效果。不知道算不算是节后习题 3 的答案。
javapublic class EuclidAlgorithms { public static void main(String[] args) { int r = getGCD(119, 544); System.out.println("119 和 544 的最大公因数是 " + r); } public static int getGCD(int m, int n) { if (m < n) { return getGCD(n, m); } int r = m % n; if (r == 0) { return n; } return getGCD(n, r); } }
5 个特征
一个算法不仅仅是一组数量有限的规则,给出求解特定一类问题的一系列操作步骤,除此之外,它还具备如下 5 个重要特征。
- 有限性(有穷性)。算法必须在执行有限步之后终止。
- 确定性。算法的每一步都必须精确定义,对于每种情况要执行的操作必须给出严格而无歧义的说明。用计算机语言表示的计算方法称为程序( program )。
- 输入。一个算法具有 0 个或者多个输入( input ):算法开始前赋给它的初始量,或者在算法执行中动态赋给它的量。这样的输入取自特定的对象集合。
- 输出。一个算法具有 1 个或者多个输出( output ):与输入有着某种指定关系的量。
- 可行性(有效性)。通常还要求算法在下述意义下是可行的:它的所有操作必须足够基本,原则上人们可以用笔和纸在有限时间内准确地执行。
我们应当指出,有限性的要求太低了,不足以满足实际应用的需求。一个有用的算法的步骤数不仅应当有限,而且应当非常有限,大小合理。
在实践中,我们不仅需要各种算法,而且还要求这些算法在广义美学意义下是好的。好算法的一个标准是算法执行时间,这可以用每一步执行的次数来表达。
算法分析(algorithmic analysis):给定一个算法,我们要确定它的性能特征。
欧几里得算法的平均执行次数为
算法分析的一般思想是,取某个特定的算法,确定它的定量特性。算法理论则完全属于另一主题,它主要研究对于计算特定量是否存在可行算法。
集合论
在本节最后,简要介绍一种方法,把数学的集合论作为算法概念的坚实基础。
我们把一种计算方法形式地定义为一个四元组
是包含子集 和 的集合。 这个应该是说
。 是从 映射到自身的函数。 关于这一点不知道我理解的对不对。
我的理解是:是一个函数,它的入参是集合 中的一个元素,它的返回值也是集合 中的一个元素。
也就是说在 下应保持点点不动;也就是说,对于 中的所有元素 , 应当等于 。 我看到这里的时候理解错了,导致后面一段迷惑了好久。
这里的应当等于 只是对于 中的任意元素,而不是 中的任意元素。也就是说 是 的一个子集( ),而这个子集中的任意元素满足 。
四个量
计算状态
使用我上面递归的例子貌似比较容易理解。这个状态集合 中的元素就相当于递归调用过程中不是最终返回结果的那次调用时的入参,是计算中间过程的状态,因为本身就是入参,所以同时也属于入参集合 。
集合
如果
以算法 E 为例,它可以用这些术语形式化地表述如下:
- 令
为所有单元素( )、所有有序数偶(序偶) 以及所有四元组 , , 的集合,其中 是正整数, 是非负整数。 - 令
为所有有序数偶 组成的 的子集, 为所有单元素( )组成的 的子集。 定义为:
这种表示法同算法 E 之间的对应是显而易见的。
这里不包含 E0。
算法概念的这种表达方式,不再涉及前面提到的可行性的限制。例如,
- 令
为字母的有限集, 为 上所有字符串的集合(所有有序序列 的集合,其中 , ( )是 中的元素)。
这步的思路是对计算状态编码,以便用
现在令
为一个非负整数, 为所有 的集合,其中 是 中的元素, 是一个整数, ; 为取 时 的子集, 为取 时 的子集。
如果
最后,令
这类计算方法的每一步显然是可行的。而且经验表明,这种模式匹配规则也足以胜任任何可以手工计算的工作。还有很多方法可以表述可行计算方法的概念(例如利用图灵机),它们在本质上是等价的。
上面这一段关于可行性限制的说明,完全没看懂。🥲
习题
[10] 正文中展示了可以利用替换记号,通过置
, , ,交换变量 和 的值。请说明可以通过一连串替换,把四个变量 重新排列成 。换句话说, 的新值是 的初始值,以此类推。试用最少的替换次数实现。 答案:
, , , , [15] 证明从步骤 E1 第二次执行起,每次该步开始时,
必然大于 (第一次执行时可能不满足)。 - 在 E2 中,
是 除 的余数,此时必然满足 。 - 执行到 E3 时,由于
, ,所以上一步的 到这一步就变成了 。 再次执行到 E1 时必然满足 。
答案:在第一次执行步骤 E1 后,变量
和 的值分别是 和 原来的值,且 。 - 在 E2 中,
[20] (为了提高效率)修改算法 E,使其避免出现
之类的平凡(频繁?)替换操作。按照算法 E 的风格写出这个新算法,将其称为算法 F。 - F1. [ 求余数。 ] 用
除 ,令 为余数。 - F2. [ 余数为 0? ] 如果
,算法终止。 是答案。 - F3. [ 求余数。 ] 用
除 ,令 为余数。 - F4. [ 余数为 0? ] 如果
,算法终止。 是答案。 - F5. [ 重复。 ] 返回步骤 F1。
更算法 E 类似也可以添加一个
的判断,避免一次多余的取余运算。 - F0. [ 保证
。 ] 如果 ,执行步骤 F3。
对比答案,比较严重的错误是缺少算法结束的符号 ▋ 。
答案:
- F1. [ 求
的余数。 ] 用 除 ,令 为余数。 - F2. [ 余数是否为 0? ] 如果
,算法终止。 是答案。 - F3. [ 求
的余数。 ] 用 除 ,令 为余数。 - F4. [ 余数是否为 0? ] 如果
,算法终止。 是答案;返回步骤 F1。 ▋
- F1. [ 求余数。 ] 用
[16] 2166 与 6099 的最大公因数是多少?
2166 和 6099 的最大公因数是 57
答案:57
[12] 说明“阅读本套数的步骤”其实不是一个真正的算法,因为在算法的五个特征中,它至少缺少三个!另外请指出它与算法 E 在格式上的差异。
“阅读本套数的步骤” 是本书开头介绍的一段阅读方法,其流程图如下:
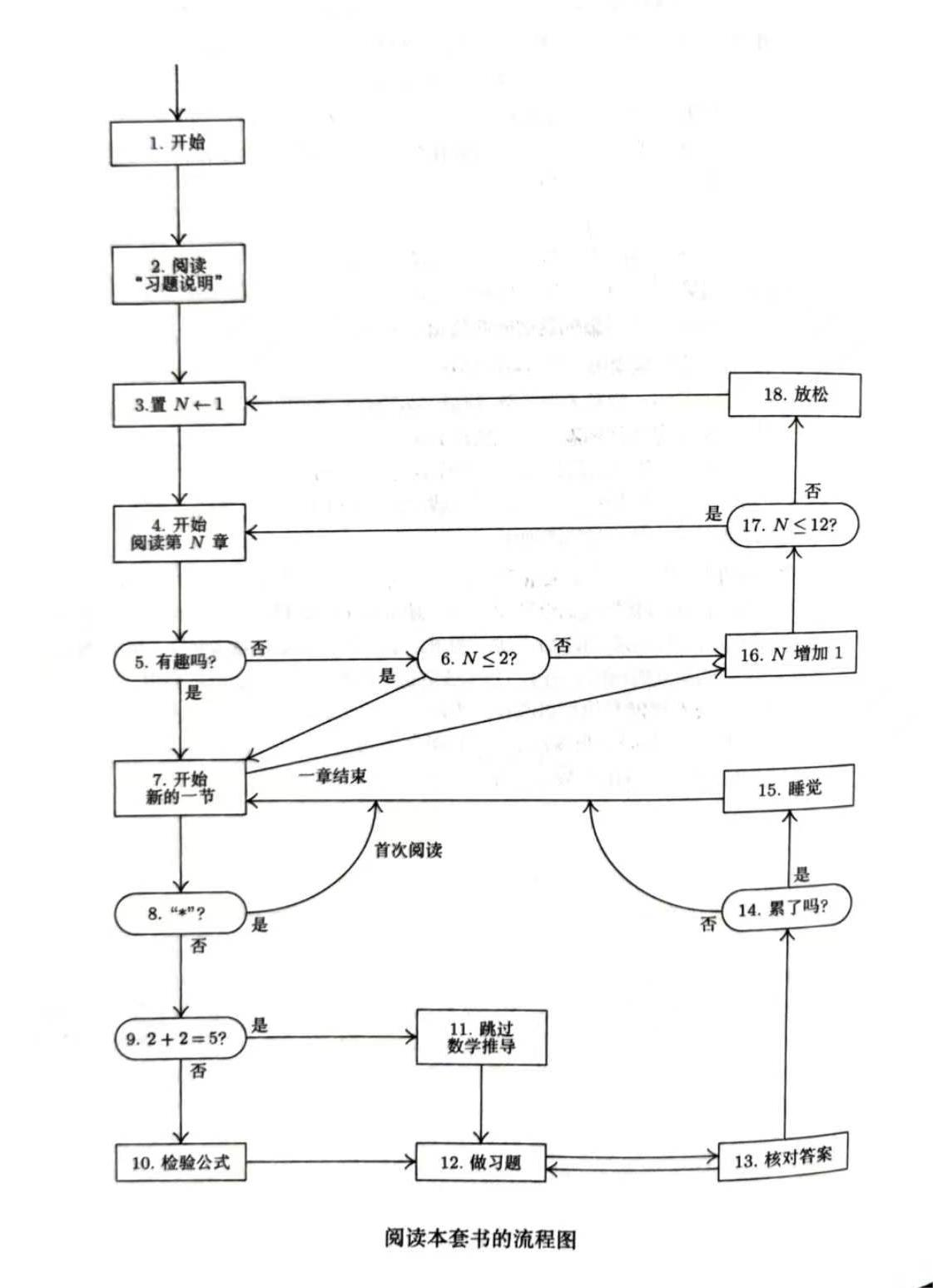
算法的五个特征:有限性(有穷性)、确定性、输入、输出 和 可行性(有效性)。
这个流程图个人认为不满足如下三个特征:有限性(有穷性):由于在时会 ,所以这个步骤不会结束,不满足有限性。 输入:这些步骤没有输入输出:这些步骤也没有输出。
答案:不满足有限性、确定性和可行性,可能没有输出。就格式而言,在操作步号码之前没有字母,未出现概述性短语,而且没有“▋” 。
[20] 当
时,执行算法 E 步骤 E1 的平均次数 是多少? 2.6?:首先
有接近 100% 的几率大于 的值 5,所以可当作 E1 肯定会执行一步,并且其中有 的几率余数为 0。之后 的值将小于 ,此时有 4 种情况: - 4:2 步
- 3:3 步
- 2:2 步
- 1:1 步
最终结果为:
答案:用
和 实验算法 E,步骤 E1 执行的次数分别为 2,3,4,3,1,所以步骤 E1 执行的平均次数是 。 答案倒是一样,不过我的解题思路和答案差的有点多。
[M21]
已知, 在所有正整数范围内取值,令 为算法 E 中步骤 E1 执行的平均次数。说明 具有合理定义。 与 有关系吗? M 难度的连题目都看不懂~~
答案:除了数目有限的特例以外,
总成立,当 时,算法 E 的第 1 次代仅仅交换这两个数,所以 . 例如 , , 1,2,3,2,1,3,4,5,4,2,3,4,5,4,2,... 的平均次数是 3.6 . [M25] 通过指定式
中 , , , ,给出计算正整数 和 的最大公因数的“可行的”形式算法。令输入由字符串 表示,也就是在 个 后连着 个 。你的解法应当力求尽可能简单。
[ 提示: 利用算法 E,把步骤 E1 中的除法改为置] 本来书中关于这段的内容就没看懂,这里的题目也没看懂。
答案也没看懂。答案:令
, ,算法结束时得到字符串 。 每次迭代要么减少
,要么保持 不变并减少 。 [M30] 假定
和 是两个计算方法。例如, 可以代表式 中的算法 E,不过要限制 和 的大小;而 可以代表算法 E 的一个计算机程序实现。(因此 可以是计算机所有状态的集合,也就是计算机内存和寄存器所有可能的配置; 可以是计算机单步操作的定义; 可以是初始状态的集合,包括确定最大公因数的相应程序以及 和 的值。) 试就“
是 的一个表示”或者“ 模拟 ”的概念,给出集合论定义。直观上,这意味着 的任何计算序列都由 模拟实现,不过 可能要用更多的计算步骤,保留更多的状态信息。(因此,我们得以严格解释“程序 是算法 的一个实现”这一陈述。) 这个答案太长了,自己也完全看不懂,就不整理出来了,有兴趣的还是直接看书吧。