
JEP 467: Markdown Documentation Comments | Markdown 文档注释
摘要
允许在 JavaDoc 文档注释中使用 Markdown 编写,而不仅仅是 HTML 和 JavaDoc @- 标签的混合。
目标
通过在文档注释中引入 Markdown 语法(与 HTML 元素和 JavaDoc 标签一起使用),使 API 文档注释的编写和阅读在源代码形式下更加容易。
不对现有文档注释的解释产生不利影响。
扩展 Compiler Tree API,以便其他分析文档注释的工具能够处理这些注释中的 Markdown 内容。
非目标
- 不旨在实现现有文档注释到 Markdown 语法的自动转换。
动机
文档注释是出现在源代码中的格式化注释,靠近它们所服务的声明。Java 源代码中的文档注释使用 HTML 和自定义 JavaDoc标签 的组合来标记文本。
1995 年选择 HTML 作为标记语言是合理的。HTML 功能强大、标准化,并且当时非常流行。但是,虽然 HTML 作为被 Web 浏览器消费的标记语言在今天仍然非常流行,但自 1995 年以来,HTML 作为人类手动生成的标记语言已经变得不那么受欢迎了,因为它编写起来很繁琐且难以阅读。如今,HTML 更常见的是从其他更适合人类的标记语言生成的。由于 HTML 编写起来很繁琐,因此编写格式良好的文档注释也很繁琐,而且由于许多新开发人员对 HTML 不熟练(因为其作为人类生成格式的衰退),这变得更加繁琐。
内联 JavaDoc 标签(如 {@link} 和 {@code})也很繁琐,开发人员对这些标签也不太熟悉,通常要求作者查阅其用法文档。最近对 JDK 源代码中的文档注释进行的分析显示,超过 95% 的内联标签用于代码片段和指向文档中其他位置的链接,这表明这些构造的更简单形式将受到欢迎。
Markdown 是一种流行的简单文档标记语言,易于阅读、编写和转换为 HTML。文档注释通常不是复杂的结构化文档,对于通常出现在文档注释中的构造(如段落、列表、样式化文本和链接),Markdown 提供了比 HTML 更简单的形式。对于 Markdown 不直接支持的构造,Markdown 也允许使用 HTML。
在文档注释中引入使用 Markdown 的能力将结合两者的优点。它将为最常见的构造提供简洁的语法,并减少对 HTML 标记和 JavaDoc 标签的需求,同时保留使用 Markdown 中不可用的功能的专用标签的能力。这将使在源代码中编写和阅读文档注释变得更加容易,同时保留生成与之前相同的生成 API 文档的能力。
描述
作为在文档注释中使用 Markdown 的示例,请考虑 java.lang.Object.hashCode 的注释:
/**
* 返回对象的哈希码值。此方法是为了支持如由
* {@link java.util.HashMap}提供的哈希表而设计的。
* <p>
* {@code hashCode}的一般约定是:
* <ul>
* <li>在 Java 应用程序的一次执行过程中,只要多次在同一对象上调用它,并且没有修改对象上用于{@code equals}比较的信息,
* {@code hashCode}方法就必须一致地返回相同的整数。
* 这个整数不必在应用程序的一次执行到另一次执行之间保持一致。
* <li>如果两个对象根据{@link #equals(Object) equals}方法是相等的,那么对这两个对象中的每一个调用{@code hashCode}方法
* 必须产生相同的整数结果。
* <li>不要求如果两个对象根据{@link #equals(Object) equals}方法是不相等的,那么对这两个对象中的每一个调用{@code hashCode}方法
* 必须产生不同的整数结果。但是,程序员应该意识到,为不相等的对象产生不同的整数结果可能会提高哈希表的性能。
* </ul>
*
* @implSpec
* 在合理可行的情况下,由类{@code Object}定义的{@code hashCode}方法为不同的对象返回不同的整数。
*
* @return 此对象的哈希码值。
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/相同的注释可以通过在 Markdown 中表达其结构和样式来编写,不使用 HTML,只使用少数几个 JavaDoc 内联标签:
/// 返回对象的哈希码值。此方法是为了支持如由
/// [java.util.HashMap] 提供的哈希表而设计的。
///
/// `hashCode`的一般约定是:
///
/// - 在 Java 应用程序的一次执行过程中,只要多次在同一对象上调用它,并且没有修改对象上用于`equals`比较的信息,
/// `hashCode`方法就必须一致地返回相同的整数。
/// 这个整数不必在应用程序的一次执行到另一次执行之间保持一致。
/// - 如果两个对象根据
/// [equals][#equals(Object)] 方法是相等的,那么对这两个对象中的每一个调用
/// `hashCode`方法必须产生相同的整数结果。
/// - 不要求如果两个对象根据 [equals][#equals(Object)] 方法是不相等的,那么对这两个对象中的每一个调用
/// `hashCode`方法必须产生不同的整数结果。但是,程序员应该意识到,为不相等的对象产生不同的整数结果可能会提高哈希表的性能。
///
/// @implSpec
/// 在合理可行的情况下,由类`Object`定义的`hashCode`方法为不同的对象返回不同的整数。
///
/// @return 此对象的哈希码值。
/// @see java.lang.Object#equals(java.lang.Object)
/// @see java.lang.System#identityHashCode(为了本示例的目的,故意避免了对文本进行诸如重新换行等外观上的更改,以便于进行前后对比。)
要观察的关键差异:
Markdown 的使用通过一种新的文档注释形式来表示,其中每行都以
///开头,而不是传统的/**...*/语法。不需要 HTML
<p>元素;空行表示段落分隔。HTML
<ul>和<li>元素被 Markdown 列表标记替换,使用-来表示列表中每个项目的开始。HTML
<em>元素被下划线(_)替换,以表示字体变化。{@code ...}标签的实例被反引号(`...`)替换,以表示等宽字体。{@link ...}链接到其他程序元素的实例被 Markdown 引用链接 的扩展形式替换。块标签(如
@implSpec、@return和@see)的实例通常不受影响,只是这些标签的内容现在也在 Markdown 中,例如这里@implSpec标签内容中的反引号。
以下是突出显示两个版本之间差异的并排截图:
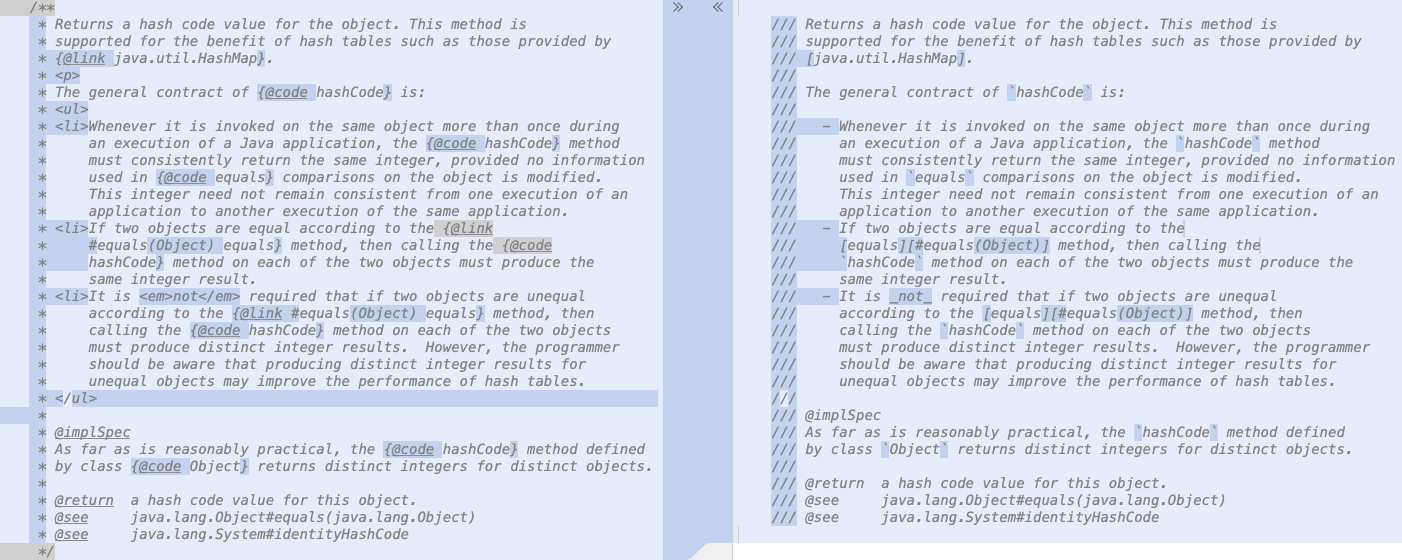
使用 /// 进行 Markdown 文档注释
我们使用 /// 进行 Markdown 注释,以克服传统 /** 注释的两个问题。
以
/*开头的块注释不能包含字符序列*/(JLS §3.7)。在文档注释中放置代码示例的情况越来越普遍。这一限制排除了不包含嵌入式/*...*/注释或包含*/字符的表达式的情况,除非使用破坏性的解决方案。在
//注释中,对行尾可能出现的字符没有限制。在以
/**开头的传统文档注释中,每行开头的空格后跟一个或多个星号是 可选的。当注释行省略这样的星号时,会与 Markdown 构造(如强调、列表项和主题分隔符)产生歧义,这些构造本身以星号开头。在
///注释中,从不存在这样的歧义。
不能更改 Java 语言的语法以允许新的注释形式。因此,任何新的文档注释风格都必须是传统的 /* ... */ 块注释或一系列 // 行尾注释的形式。
上述观点证明了使用行尾注释代替传统注释的合理性,但问题仍然存在:如何区分文档注释和其他行尾注释。我们使用额外的 /,这与在传统文档注释开头使用额外的 * 相呼应。此外,虽然不是主要考虑因素,但其他支持行尾文档注释的语言(如 C#、Dart 和 Rust)已经成功使用 /// 作为文档注释一段时间了。
语法
Markdown 文档注释使用 Markdown 的 CommonMark 变体编写。对链接的增强允许方便地链接到其他程序元素。支持简单的 GFM 管道表,并支持所有 JavaDoc 标签。
链接
您可以通过使用 Markdown 引用链接 的扩展形式,创建指向 API 中其他地方声明的元素的链接,其中引用标签来自对元素本身的标准 JavaDoc 引用。
要创建文本源自元素标识的简单链接,只需将对元素的引用放在方括号中即可。例如,要链接到 java.util.List,您可以写 [java.util.List],或者在代码中有 java.util.List 的 import 语句时,只需写 [List]。链接的文本将以等宽字体显示。该链接相当于使用标准的 JavaDoc {@link ...} 标签。
您可以链接到任何类型的程序元素:
/// - 一个模块 [java.base/]
/// - 一个包 [java.util]
/// - 一个类 [String]
/// - 一个字段 [String#CASE_INSENSITIVE_ORDER]
/// - 一个方法 [String#chars()]要创建带有替代文本的链接,请使用 [text][element] 形式。例如,要创建指向 java.util.List 的文本为 a list 的链接,您可以写 [a list][List]。链接将以当前字体显示,但您可以在文本中使用格式标记。该链接相当于使用标准的 JavaDoc {@linkplain ...} 标签。
例如:
/// - [`java.base`模块][java.base/]
/// - [`java.util`包][java.util]
/// - [一个类][String]
/// - [一个字段][String#CASE_INSENSITIVE_ORDER]
/// - [一个方法][String#chars()]在引用链接中,您必须转义任何方括号的使用。这可能在引用具有数组参数的方法时出现;例如,您会将 String.copyValueOf(char[]) 的链接写为 [String#copyValueOf(char\[\])]。
您可以使用 Markdown 链接的所有其他形式,包括到 URL 的链接,但链接到其他程序元素可能是最常见的。
表格
支持简单表格,使用 GitHub Flavored Markdown 的语法。例如:
/// | Latin | Greek |
/// |-------|-------|
/// | a | alpha |
/// | b | beta |
/// | c | gamma |不支持可能需要的标题和其他无障碍特性。在这种情况下,仍建议使用 HTML 表格。
JavaDoc 标签
在 Markdown 文档注释中,可以使用 JavaDoc 标签,包括 内联标签(如 {@inheritDoc})和 块标签(如 @param 和 @return):
/// {@inheritDoc}
/// 此外,此方法调用 [#wait()].
///
/// @param i 索引
public void m(int i) ...JavaDoc 标签不能在字面文本中使用,如 代码跨度(`...`)或代码块,即要么 缩进 的文本块,要么用 围栏(如 ``` 或 ~~~)括起来的文本块。换句话说,在代码跨度和代码块中,@... 和 {@...} 字符序列没有特殊含义:
/// 下面的代码跨度包含字面文本,而不是 JavaDoc 标签:
/// `{@inheritDoc}`
///
/// 在下面的缩进代码块中,`@Override` 是一个注解,
/// 而不是 JavaDoc 标签:
///
/// @Override
/// public void m() ...
///
/// 同样,在下面的围栏代码块中,`@Override` 是一个注解,
/// 而不是 JavaDoc 标签:
///
/// ```
/// @Override
/// public void m() ...
/// ```对于那些可能包含带标记文本的标签,在 Markdown 文档注释中,该标记也是 Markdown 格式:
/// @param l 列表,如果没有列表,则为 `null`{@inheritDoc} 标签会合并一个或多个超类型中方法的文档。包含该标签的注释的格式不需要与被继承的文档注释的格式相同:
interface Base {
/** 一个方法。 */
void m()
}
class Derived implements Base {
/// {@inheritDoc}
public void m() { }
}用户定义的 JavaDoc 标签可以在 Markdown 文档注释中使用。例如,在 JDK 文档中,我们定义并使用 {@jls ...} 作为指向 Java 语言规范的链接的简写形式,以及块标签(如 @implSpec 和 @implNote)来引入特定信息的部分:
/// 有关注释的更多信息,请参阅{@jls 3.7 Comments}。
///
/// @implSpec
/// 此实现不执行任何操作。
public void doSomething() { }独立 Markdown 文件
doc-files 子目录中的 Markdown 文件将以类似于此类目录中 HTML 文件的方式被适当处理。此类文件中的 JavaDoc 标签将被处理。页面标题从第一个标题中推断得出。不支持如 PandocMarkdown 处理器所支持的 YAML 元数据。
用于生成顶级 概述页面 的内容文件也可以是 Markdown 文件。
语法高亮和嵌入式语言
围栏代码块 的开头围栏后可能跟随一个 信息字符串。信息字符串的第一个单词用于在相应的生成 HTML 中派生 CSS 类名,也可能被 JavaScript 库用于启用语法高亮(如使用 Prism)和渲染图表(如使用 Mermaid)。
例如,结合适当的库,这将显示带有语法高亮的 CSS 代码片段:
/// ```css
/// p { color: red }
/// ```您可以通过使用 javadoc 的 --add-script 选项将 JavaScript 库添加到您的文档中。
语法细节
由于 Markdown 文本每行开头和结尾的水平空白可能很重要,因此 Markdown 文档注释的内容确定如下:
从每行中删除任何前导空白和三个初始
/字符。通过删除前导空白字符,将行向左移动,直到前导空白最少的非空行没有剩余的前导空白。
保留每行中额外的前导空白和任何尾随空白,因为它们可能很重要。例如,行首的空白可能表示 缩进代码块 或列表项的继续,而行尾的空白可能表示 硬换行。
(删除前导偶然空白的策略类似于 String.stripIndent(),但无需处理尾随的空行。)
注释每行 /// 之后的字符没有限制。特别是,注释可能包含代码示例,这些代码示例可能包含它们自己的注释:
/// 这是一个示例:
///
/// ```
/// /** Hello World! */
/// public class HelloWorld {
/// public static void main(String... args) {
/// System.out.println("Hello World!"); // 传统示例
/// }
/// }
/// ```除了用于视觉上区分新类型的文档注释外,使用行尾(//)注释还消除了使用传统(/* ... */)注释时注释内容所固有的限制。特别是,在传统注释中无法使用字符序列 */(JLS §3.7),但在编写包含传统注释、包含 glob 表达式的字符串和包含正则表达式的字符串的示例代码时,可能需要这样做。
要在注释中包含空行,它必须以任何可选的空白开头,然后是 ///:
/// 这是一个示例 ...
///
/// ... 包含空行的 3 行注释。完全空白的行将导致任何前后的注释被视为单独的注释。在这种情况下,除最后一个注释外,所有注释都将被丢弃,并且只有最后一个注释被视为可能跟随的任何声明的文档注释:
/// 此注释将被视为“悬空注释”并被忽略。
/// 这是以下声明的注释。
public void m() { }在两个 /// 注释之间出现的任何不以 /// 开头的其他注释也是如此。
API 与实现
在 Compiler Tree API 中,解析后的文档注释由 com.sun.source.doctree 包中的元素表示。
我们引入了一种新的树节点类型 RawTextTree,其中包含未解释的文本,以及一种新的树节点类型 DocTree.Kind.MARKDOWN,它指示 RawTextTree 中的 Markdown 内容。我们向 DocTreeVisitor 及其子类型 DocTreeScanner 和 DocTreePathScanner 添加了对应的新 visitRawText 方法。
具有 MARKDOWN 类型的 RawTextTree 节点表示 Markdown 内容,包括 HTML 构造,但不包括任何 JavaDoc 标签,如 {@inheritDoc} 和 @param。
Markdown 文本的处理分为两个阶段:
解析 —— Markdown 注释被解析成一系列
RawTextTree节点,每个节点具有DocTree.Kind.MARKDOWN类型并包含 Markdown 内容,这些节点与用于内联和块标签的标准DocTree节点交错排列。内联和块标签的解析方式与传统的文档注释相同,不同之处在于标签内容也被解析为 Markdown。节点序列以正常方式存储在DocCommentTree节点中。与传统的文档注释不同,HTML 构造不会被解析为对应的
DocTree节点,因为需要考虑太多的上下文。然后对初始解析生成的
DocCommentTree中的 Markdown 内容进行检查,查找任何没有关联 链接引用定义 的 引用链接,且其 链接标签 在语法上与对程序元素的引用相匹配的链接。任何此类链接都将被替换为代表{@link ...}或{@linkplain ...}的等效节点。渲染 ——
javadoc工具将DocCommentTree渲染成适合包含在正在生成的页面中的 HTML。任何
RawTextTree节点和其他节点的序列都将转换成一个包含RawTextTree节点文本的单个字符串,其中非 Markdown 内容由 Unicode 对象替换字符(U+FFFC)表示。Markdown 处理器将结果字符串进行渲染,然后在结果输出中将U+FFFC字符替换为非 Markdown 内容节点的渲染形式。虽然大多数渲染都很直接,但 Markdown 标题需要特别注意:
根据封闭上下文调整标题级别。这适用于标题最初在文档注释中以 ATX 样式标题(使用
#字符前缀表示级别)或 Setext 样式标题(使用=或-下划线表示级别)的形式编写的情况。例如,在模块、包或类的文档注释中的 1 级标题在生成的页面中渲染为 2 级标题,而在字段、构造函数或方法的文档注释中的 1 级标题在生成的页面中渲染为 4 级标题。
此调整仅适用于 Markdown 标题,不适用于 HTML 标题的直接使用。
在渲染的 HTML 中包含
id标识符属性,以便可以从其他位置轻松引用标题。标识符根据标题内容生成,与javadoc生成的其他标识符的方式相同。(在浏览器中查看标题时,通过点击弹出链接图标,您可以轻松获得指向标题的链接。)将标题的文本添加到生成的文档的主要搜索索引中。
实现利用了广为人知的 commonmark-java 库的内部副本。按设计,库的使用不会在任何受支持的 JDK 公共 API 中显示。
这里描述的大多数特性都是 JDK 的 javadoc 工具和 jdk.javadoc 模块中 Compiler Tree API 的一部分。然而,在标准 Java API 中有一个地方可以观察到文档注释新样式的使用:在 java.compiler 模块中的方法 javax.lang.model.util.Elements.getDocComment,该方法如果有的话,会返回声明对应的文档注释的规范化文本。我们将更新这个方法以包含 /// 注释。此外,由于注释的类型会影响其解释,我们将提供一个新方法来判断一个声明的文档注释是否使用传统的 /** ...*/ 块注释形式或新的 /// 行尾注释形式。
未来工作
可以检测到一些格式化的标题使用,后面跟着相应的内容,并将它们转换为等效的 JavaDoc 标签。
例如,一个标题为 Parameters,后面跟着参数名称及其描述的列表,可以转换为等效的 @param 标签:
注释
markdown# Parameters * x x 坐标 * y y 坐标转换
java@param x x 坐标 @param y y 坐标
类似的策略也可以用于方法可能抛出的异常列表:
注释
markdown# Throws * NullPointerException 如果第一个参数为`null` * NullPointerException 如果第二个参数为`null` * IllegalArgumentException 如果参数不被接受转换
java@throws NullPointerException 如果第一个参数为`null` @throws NullPointerException 如果第二个参数为`null` @throws IllegalArgumentException 如果参数不被接受
一个方法只应有一个返回值描述,所以在这个情况下不需要使用列表:
注释
markdown# Returns 参数的平方根转换
java@return 参数的平方根
提出的这些形式看起来像是普通的 Markdown,但它们也占用了更多的垂直空间。开发者可能更倾向于使用更简洁的形式,即使用旧式的 JavaDoc 标签。
虽然可能很难将这种策略扩展到所有块标签,包括用户指定的标签,但在 JDK 代码库中,只有五个标签(@param、@return、@see、@throws 和 @since)占用了超过 90% 的块标签使用。
备选方案
可插拔实现
我们可以不利用特定的 Markdown 解析器实现,而是支持使用其他用户指定的 Markdown 处理器,以提供不同风格的 Markdown。然而,这种方法在生成跨不同库的文档时可能会导致不一致性,而获得的收益却很小。
将更多 Markdown 转换为 HTML
我们可以将额外的 Markdown 结构转换为等效的 DocTree 节点,这些节点表示纯文本、HTML 和 JavaDoc 标签。虽然这种方法具有 API 客户端可能不需要知道注释的原始来源是 Markdown 的优势,但也存在一些缺点:
表示与原始语法树的差异越大,在需要时提供准确且相关的诊断就越难。该元素的消息可能会令人困惑。
在为从 Markdown 结构派生的 HTML 元素合成
DocTree节点时,很难给出与该节点在原始注释中位置相关的准确位置信息,因为该节点在原始注释中没有表示。最多,您只能给出一个附近的位置。这个问题在 Java 编译器javac中类似于为合成元素(如默认的无参构造函数或桥接方法)分配位置时遇到的问题。一般解决方案很难实现,因为它需要了解可能涉及的任何和所有 JavaDoc 标签,因为许多标签允许丰富的内容(如 Markdown 或 HTML)作为其内容的一部分但不是全部。
例如,
@param标签在描述之前会跟一个参数名,如果名称是类型参数的名称,则可能用<...>括起来。将该名称解释为 HTML 片段是错误的。同样,@serialField标签在描述之前会跟一个名称和一个类型。虽然这些是标准 doclet 已知的标准标签,但 doclet 也允许使用用户定义的标签。
内联标签
虽然大多数块标签的使用可以通过使用标题和后续内容的格式化来替换,但大多数不太常见的内联标签却没有这样的等效物。其中,{@inheritDoc} 是最常见的,而在 Markdown 中没有明显的对应物。与其为了它而发明另一种语法,似乎继续使用现有的内联标签语法更为合适。
/**...*/ 注释中的 Markdown
如上所述,使用 /// 进行文档注释有许多优点。暂且不论这些原因,如果我们想解析嵌入在传统 /**...*/ 注释中的 Markdown,而不是或除了引入 /// 注释之外,那么有两种可能性:要么将所有现有的 /** 注释视为 Markdown 注释,要么在每个 /** 注释内部编码一种方式来区分 Markdown 注释和传统注释。
将现有注释视为 Markdown 是不可行的,因为 Markdown 和 HTML 是具有不同语法规则的不同语言。在 HTML 中,空白字符仅在 <pre> 元素中的文本字面上才有意义。相比之下,在 Markdown 中,垂直空白字符可能表示段落分隔,前导水平空白字符可能表示缩进的代码块或嵌套列表,尾随空白字符可能表示硬换行,这在 HTML 中相当于 <br>。此外,在 Markdown 文档中使用 HTML 的 规则 有些复杂且不够直观。最后,JDK 代码中有很多在叙述文本中使用方括号的例子,这可能会被错误地解释为指向程序元素的链接;例如,“The information is returned as a two-dimensional array (array[x][y])”。
在每个 /** 注释内部编码注释类型的文档是可能的,但不太吸引人。例如,我们可以在初始的 /** 后面立即放置一个短字符串,以指示随后的文本应被视为 Markdown:
/**md
* Hello _World!_
*/当我们对这个方法进行原型设计时,它普遍不受欢迎,因为它被认为在小注释中过于突兀,在大注释中又不够显著。
可配置的注释样式
我们可以构建一个可配置的系统,该系统接受一些以 Markdown 编写的 /** ... */ 文档注释,以及以 HTML 编写的其他注释。然而,不清楚这样的机制是否比更明显地使用 /// 注释进行 Markdown 注释和继续使用 /** ... */ 进行 HTML 注释具有任何显著优势。
风险与假设
实现采用第三方库 commonmark-java 来将 Markdown 转换为 HTML。如果该库不再维护,我们将不得不维护该库的一个分支以供 JDK 使用,或者找到等效的替代方案。
由于检查错误代码的能力降低,以及作者有时会忘记检查其文档的生成形式,因此生成的 API 文档中可能会出现更多错误。
例如,在传统的文档注释中,包含未终止的
code标签(如{@code abc)的段落将在调用 JavaDoc 时发出诊断消息,并在生成的文档中显示为 ▶ invalid @code。在 Markdown 中,等效的未闭合代码跨度`abc被指定为按字面文本处理,并将以这种方式显示,而没有相应的诊断消息。